Application Perimeter: Why AI Agents Need Resource-Level Access Control

In the previous post, we walked through how AI gateways sit between an autonomous agent and the enterprise apps it wants to touch. We talked about inbound auth, outbound auth, the gap between OAuth scopes and tool-level enforcement, and the kind of policy decisions a gateway needs to make on every single call.
Once the gateway is in place and you start writing policies for it, a quieter problem shows up. Most policy frameworks built around MCP today let you say which tool an agent can call. However, they may not give you visibility into where the agent can truly act.
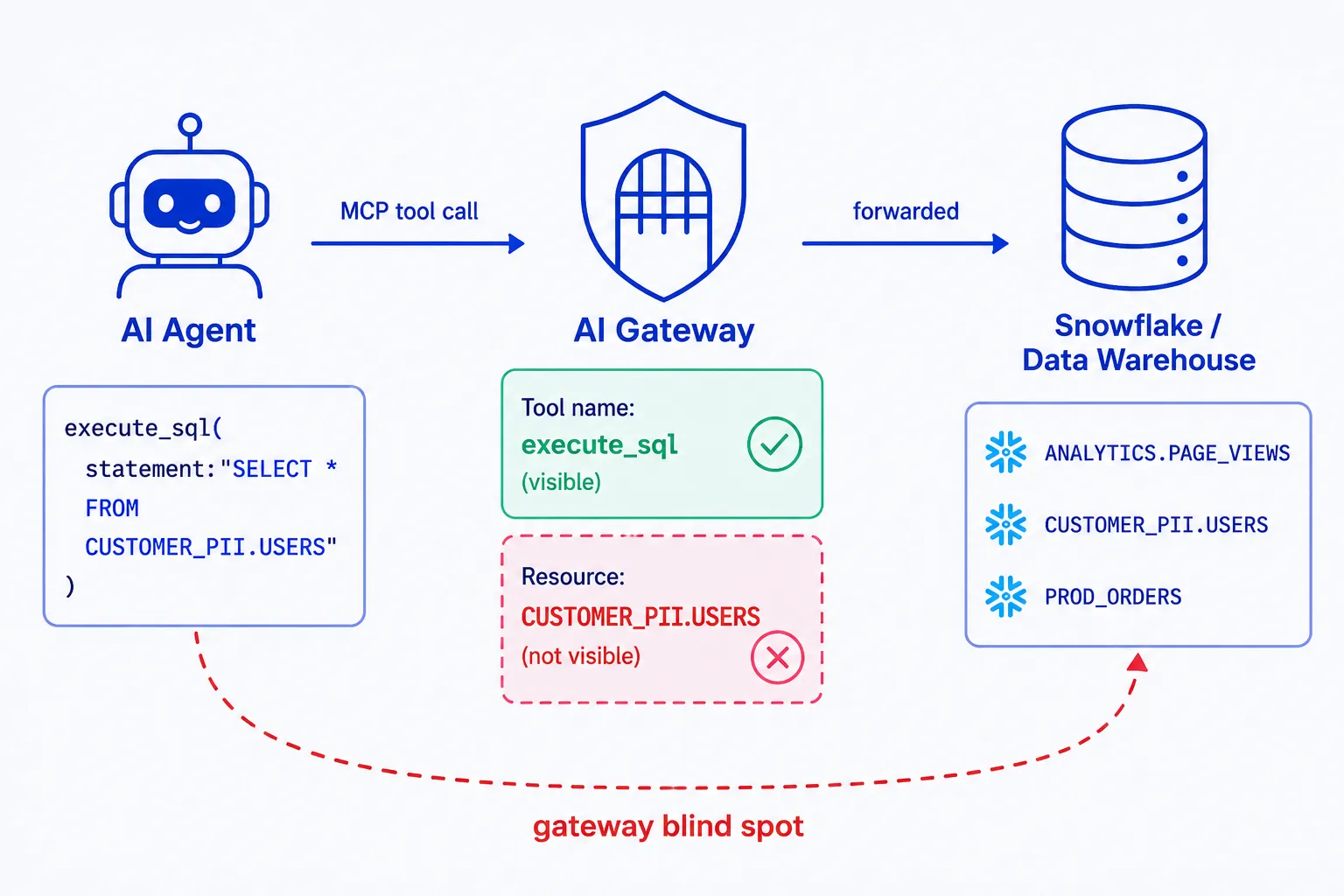
Let’s take an MCP server in front of an enterprise data warehouse like Snowflake, and an agent that has been granted access to a tool called execute_sql. From an OAuth point of view, the call looks fine. The agent has the right token, the tool name is on the allowlist, and the request goes through.
Now look at the body of the request:
SQL
execute_sql(
warehouse: "ANALYTICS_WH",
statement: "SELECT email, ssn, date_of_birth FROM CUSTOMER_PII.USERS LIMIT 10000"
)
The decision made on the tool says: this agent is allowed to call execute_sql. The decision we did not make was: this agent is allowed to pull ten thousand rows of regulated personal data out of CUSTOMER_PII.USERS.
If the SQL body happens to be DROP TABLE PROD_ORDERS instead of a SELECT, the governance layer has the exact same blind spot—only now the cost is an outage instead of a leak.
The OAuth scope that governs this call is broad by design. Snowflake’s OAuth integration hands the agent a session in whichever role it has been mapped to, and the role decides what the session can touch.
This is not a Snowflake problem. It shows up the same way with GitHub repositories, Jira projects, S3 buckets, Salesforce records, and any system where one connector covers many resources.
MCP Is Great, But…
MCP is a highly useful protocol for agent-to-tool communication. It standardizes how an agent discovers tools, calls them, and receives structured results.
What MCP does not do—and probably was never meant to do—is reason about the data inside the tool call. The repo name is an argument. The Snowflake table could be an argument. The S3 bucket could be an argument. To the protocol layer, these are opaque strings inside a JSON body. MCP cannot tell us whether payments-prod is sensitive or whether agent-sandbox is a throwaway environment.
From a governance perspective, however, controlling this is a critical aspect of application access.
Finer Scopes
When this gap shows up, we could ask the upstream provider for finer scopes. Sometimes that may work, but most often, it won't. Most SaaS platforms and cloud providers do not split their OAuth scope vocabulary by resource because their own access models were never designed at the OAuth layer. Resource-level access on these platforms is expressed in IAM bindings, role assignments, project memberships, repository ACLs, group memberships, table grants, and so on.
The result is a strange split. The OAuth layer says yes or no on whether the agent can call the tool. The downstream application enforces whether the human or service identity the call lands on actually has rights to the resource.
Governance Through Policies
A useful policy on top of MCP needs more than the agent identity and the tool name. At a minimum, it needs four things:
- The human the agent is acting for, when there is one.
- The agent itself.
- The tool being called.
- The resource the tool is operating on.
While the policy can grant broader-level access, the conditions it applies to must be able to point to the exact data or resources it impacts.
The Hard Problem
As agents become more reliable, they are getting pulled into workflows that actually matter: Database migrations. Infrastructure changes. Customer refunds. Entitlement updates. Code that ships. First-responder action on operational alerts.
The failure mode is no longer “wrong summary.” It is “wrong table dropped” or “wrong customer refunded.”
In each of those workflows, the resource the agent ends up touching is not knowable upfront. The tool name is fixed. The scope is fixed. The actual target depends on what the agent finds in the moment, what the human asks for, what an upstream system reports, or what the previous step decided. The whole reason the agent is useful is that it chooses its target dynamically.
The question quietly shifts from, “Is this agent allowed to use this tool?” to “Is this agent, acting for this person, allowed to do this thing to this specific resource, right now, given everything else that is true about the session?”
That is a much harder question, and the further agents move into critical workflows, the more often it has to be answered correctly.
This is the territory enterprise application access management has lived in for a long time.
Conclusion
A lot of the agent security conversation right now is about identity—for example, how to cryptographically prove the agent is who it says it is. However, it’s equally important to look at the ground rules around access to critical applications.
At Andromeda, we keep coming back to that framing. Cryptographic identity gets the agent to the door. Application access management is what tells you which rooms it is allowed to walk into once it is inside. Both have to be solved. The access guidelines for these applications have been established in the enterprise for years; we simply need the ability to seamlessly apply them to agent access as well.
Check out other blogs in the series:
In the previous post, we walked through how AI gateways sit between an autonomous agent and the enterprise apps it wants to touch. We talked about inbound auth, outbound auth, the gap between OAuth scopes and tool-level enforcement, and the kind of policy decisions a gateway needs to make on every single call.
Once the gateway is in place and you start writing policies for it, a quieter problem shows up. Most policy frameworks built around MCP today let you say which tool an agent can call. However, they may not give you visibility into where the agent can truly act.
Let’s take an MCP server in front of an enterprise data warehouse like Snowflake, and an agent that has been granted access to a tool called execute_sql. From an OAuth point of view, the call looks fine. The agent has the right token, the tool name is on the allowlist, and the request goes through.
Now look at the body of the request:
SQL
execute_sql(
warehouse: "ANALYTICS_WH",
statement: "SELECT email, ssn, date_of_birth FROM CUSTOMER_PII.USERS LIMIT 10000"
)
The decision made on the tool says: this agent is allowed to call execute_sql. The decision we did not make was: this agent is allowed to pull ten thousand rows of regulated personal data out of CUSTOMER_PII.USERS.
If the SQL body happens to be DROP TABLE PROD_ORDERS instead of a SELECT, the governance layer has the exact same blind spot—only now the cost is an outage instead of a leak.
The OAuth scope that governs this call is broad by design. Snowflake’s OAuth integration hands the agent a session in whichever role it has been mapped to, and the role decides what the session can touch.
This is not a Snowflake problem. It shows up the same way with GitHub repositories, Jira projects, S3 buckets, Salesforce records, and any system where one connector covers many resources.
MCP Is Great, But…
MCP is a highly useful protocol for agent-to-tool communication. It standardizes how an agent discovers tools, calls them, and receives structured results.
What MCP does not do—and probably was never meant to do—is reason about the data inside the tool call. The repo name is an argument. The Snowflake table could be an argument. The S3 bucket could be an argument. To the protocol layer, these are opaque strings inside a JSON body. MCP cannot tell us whether payments-prod is sensitive or whether agent-sandbox is a throwaway environment.
From a governance perspective, however, controlling this is a critical aspect of application access.
Finer Scopes
When this gap shows up, we could ask the upstream provider for finer scopes. Sometimes that may work, but most often, it won't. Most SaaS platforms and cloud providers do not split their OAuth scope vocabulary by resource because their own access models were never designed at the OAuth layer. Resource-level access on these platforms is expressed in IAM bindings, role assignments, project memberships, repository ACLs, group memberships, table grants, and so on.
The result is a strange split. The OAuth layer says yes or no on whether the agent can call the tool. The downstream application enforces whether the human or service identity the call lands on actually has rights to the resource.
Governance Through Policies
A useful policy on top of MCP needs more than the agent identity and the tool name. At a minimum, it needs four things:
- The human the agent is acting for, when there is one.
- The agent itself.
- The tool being called.
- The resource the tool is operating on.
While the policy can grant broader-level access, the conditions it applies to must be able to point to the exact data or resources it impacts.
The Hard Problem
As agents become more reliable, they are getting pulled into workflows that actually matter: Database migrations. Infrastructure changes. Customer refunds. Entitlement updates. Code that ships. First-responder action on operational alerts.
The failure mode is no longer “wrong summary.” It is “wrong table dropped” or “wrong customer refunded.”
In each of those workflows, the resource the agent ends up touching is not knowable upfront. The tool name is fixed. The scope is fixed. The actual target depends on what the agent finds in the moment, what the human asks for, what an upstream system reports, or what the previous step decided. The whole reason the agent is useful is that it chooses its target dynamically.
The question quietly shifts from, “Is this agent allowed to use this tool?” to “Is this agent, acting for this person, allowed to do this thing to this specific resource, right now, given everything else that is true about the session?”
That is a much harder question, and the further agents move into critical workflows, the more often it has to be answered correctly.
This is the territory enterprise application access management has lived in for a long time.
Conclusion
A lot of the agent security conversation right now is about identity—for example, how to cryptographically prove the agent is who it says it is. However, it’s equally important to look at the ground rules around access to critical applications.
At Andromeda, we keep coming back to that framing. Cryptographic identity gets the agent to the door. Application access management is what tells you which rooms it is allowed to walk into once it is inside. Both have to be solved. The access guidelines for these applications have been established in the enterprise for years; we simply need the ability to seamlessly apply them to agent access as well.
Check out other blogs in the series: