Avoiding Approval Fatigue with Behavior Baselines
In our recent posts, we worked our way through the hardest parts of AI agent security, one layer at a time. We established that cryptographic identity gets an agent to the door, resource governance determines which rooms it may enter, and the agent's actual access is bounded by the real-time permissions of the human in the loop.
Each time, the AI Gateway emerged as the sole architectural point with enough cross-silo visibility to enforce these rules.
But once you accept the gateway as your ultimate enforcement point, a very practical, real-world problem walks in right behind it: enforcement that requires a human to decide on every single API call does not scale. It quickly collapses into approval fatigue. And let’s be honest—a tired approver is just a rubber stamp wearing a security badge.
The High Cost of Fine-Grained Friction
Consider a mature enterprise that has done the heavy identity lifting. They have agent identities, a robust policy engine, and a gateway enforcing access to applications. The agents are active and productive.
Now, the application administrator has to live with the system. This means making daily, high-stakes choices: Do you grant standing access, or do you require step-up authorization for every single agent and tool?
- The Conservative Route: You bury your administrators under a mountain of approval requests, killing the exact velocity the agents were built to deliver.
- The Optimistic Route: You over-authorize access, exposing the enterprise to massive, silent compromises.
Making these decisions is hard enough on its own, but doing it in isolation for a single application is nearly impossible. A tool access might look completely benign in the vacuum of one application, but when viewed in the context of the agent’s overall function across the enterprise, it could be highly abnormal.
Why Traditional IAM Gets Brittle
The natural instinct from classic Identity and Access Management (IAM) is to pre-authorize access through static policies. That model worked beautifully when the caller population was human and the system cardinality was predictable.
Agent sprawl completely breaks those architectural assumptions for three core reasons:
- An Order of Magnitude More Identities: Enterprises are deploying multiple specialized agents for each individual human user, sending the identity population skyrocketing.
- Multi-Application Access: An agent rarely lives in a single silo. Its entire value proposition relies on seamlessly spanning multiple enterprise systems to get a job done.
- Short-Lived Lifecycles: Many agents are ephemeral. They spin up to execute a specific, time-bound task and tear down within minutes.
You cannot manually create a fine-grained, static policy for every single agent that accurately predicts what should be standing access versus what requires a human interrupt. Static policies simply cannot scale to this velocity or volume.
Standing Access is About Behavior, Not Policy
Deciding what is harmless enough to allow without a human prompt is a question about what normal looks like—and static policy alone cannot answer it.
Policy can tell you that an agent is technically permitted to execute queries. It cannot tell you that this specific agent, acting for a specific team, has read the exact same three database tables every weekday afternoon for the last two months and has never once written a single entry.
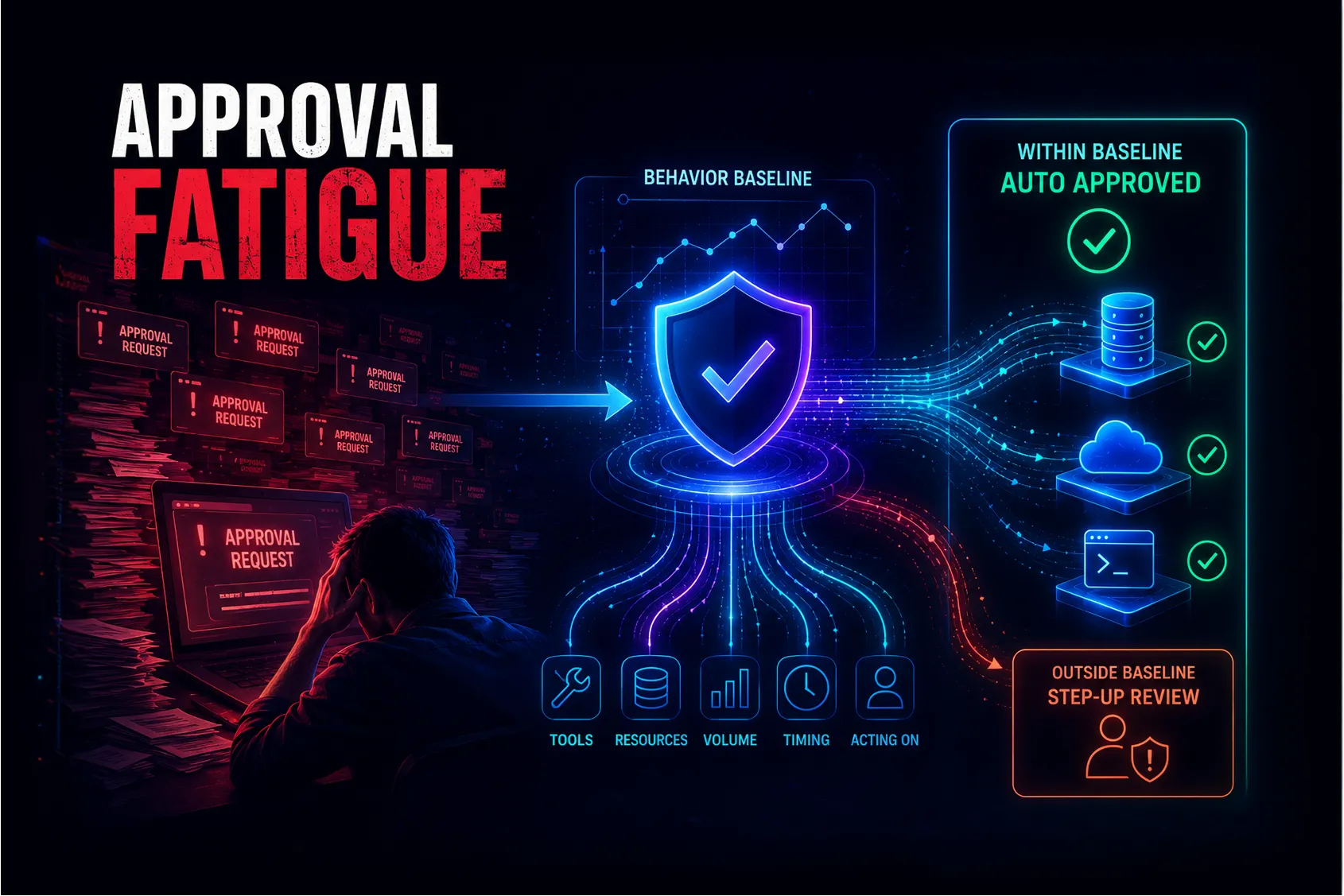
The way forward is to build a behavioral baseline model for each individual agent to mathematically define its ordinary operational shape, tracking variables like:
- Which tools are invoked across various systems
- Which underlying resources are touched
- Data volume and payload sizes
- Timing patterns and execution schedules
- On whose behalf the agent is acting
The Core Philosophy: The point of a behavioral baseline is to earn the architectural right to stop asking for permission. Once the system maps out this baseline model, the administrator simply reviews and approves the agent's expected behavioral "shape." The system then automates everything inside those boundaries, allowing routine calls to flow seamlessly as standing access.
A Baseline is Only as Sharp as its Dimensions
The accuracy of this baseline relies entirely on the resolution of the data you feed it. As we’ve argued before, governing tools alone is insufficient—you must govern the specific resources those tools operate on. Knowing that an agent called run_query tells you nothing about whether it hit public marketing tables or a restricted finance schema.
That exact visibility gap reappears the moment you try to build a behavior model. If you learn an agent's normal shape only at the tool level, your model simply records that it calls run_query on weekday afternoons. You have successfully described the verb while staying completely blind to the object.
At the tool layer, an agent that safely reads public marketing data looks identical to an agent that is quietly draining your core financial ledger. They look like the exact same Model Context Protocol (MCP) tool call.
The resource is the critical dimension that makes the behavior model honest. With it, "this agent runs queries" becomes "this agent reads these specific tables, for these specific users, at this volume." Without the resource dimension, a behavioral model is fundamentally blind.
Deviation is the Trigger, Not the Verdict
If standing access is what sits comfortably inside the baseline, then a baseline deviation is what pulls a call back into review—even if the underlying tool permission is technically valid. If an agent that has only ever touched marketing data suddenly reaches for a finance table, its tool permission hasn't expired, but its behavioral intent has drifted.
Because 90% of enterprise applications lack the native capability to detect these anomalies, the inline AI Gateway is the ideal place to handle this problem.

Sitting between the agent and your applications, the gateway has the global visibility required to look across silos. It maps out the agent's broad operational blueprint, detects structural deviations in flight, and dynamically triggers human approval before letting a risky call through.
The next step for the AI Gateway is using this rich context to derive intent. By understanding the broader mission of the caller, the gateway can examine a tool invocation and recognize that, for Agent-1, this is a completely valid access to a specific resource, whereas for Agent-2, the same call is highly suspect and must trigger a human-in-the-loop.
Turning Deviations into Decisions Without Drowning Admins
A deviation queue that routes every single anomaly to a human administrator will quickly be ignored. Not every behavioral drift carries the same architectural weight. A minor variance in query volume during a peak business cycle is fundamentally different from an uncharacteristic write operation against a production database.
To keep things manageable, the gateway scores deviations dynamically by evaluating contextual risk signals:
How This Works in Practice
Consider a reporting agent whose baseline consists of read-only access to analytics tables on behalf of the finance team during standard business hours.
Scenario A: Automated Clearance:
- One afternoon, the agent issues a read against a new analytics table it has never touched before. This is a behavioral deviation, so it exits standing access. However, the gateway evaluates the context: it’s a read operation, the table sits within the same authorized analytics schema, and the human analyst in the loop has valid corporate entitlements to that data.
- The Verdict: The risk score is low. The gateway auto-approves the call, updates the baseline, and writes a structured log to the audit ledger. The administrator is never interrupted.
Scenario B: Human Escalation
- The exact same agent, operating at midnight on behalf of a user who left the finance department last quarter, issues a write command against a core production database.
- The Verdict: The deviation triggers, but resource sensitivity, anomalous timing, and stale human entitlements push the risk score to its maximum threshold. The gateway halts execution and escalates the request to the admin queue—already enriched with the exact context explaining why it was flagged.
The goal of automated triage is not to completely eliminate the human element from enterprise security. It is to focus human attention exclusively on the exceptions where that attention actually alters the outcome.
Conclusion
Cryptographic identity gets the agent to the door. Resource governance and the user’s real permissions decide which rooms it may legally enter. Behavior baselines, learned and enforced at the AI Gateway, decide which of those entries are routine enough to be waved through and which genuinely require human intervention.
By mapping the agent's intent across multiple applications, the gateway serves as the thin line between an intelligent security control that holds and an infrastructure team that has tuned out the noise.
At Andromeda, we are building agentic security along exactly these lines. We extend our context of human and non-human identity so that standing access, deviation tracking, and risk-based approvals operate seamlessly, securely, and quietly on your behalf.
In our recent posts, we worked our way through the hardest parts of AI agent security, one layer at a time. We established that cryptographic identity gets an agent to the door, resource governance determines which rooms it may enter, and the agent's actual access is bounded by the real-time permissions of the human in the loop.
Each time, the AI Gateway emerged as the sole architectural point with enough cross-silo visibility to enforce these rules.
But once you accept the gateway as your ultimate enforcement point, a very practical, real-world problem walks in right behind it: enforcement that requires a human to decide on every single API call does not scale. It quickly collapses into approval fatigue. And let’s be honest—a tired approver is just a rubber stamp wearing a security badge.
The High Cost of Fine-Grained Friction
Consider a mature enterprise that has done the heavy identity lifting. They have agent identities, a robust policy engine, and a gateway enforcing access to applications. The agents are active and productive.
Now, the application administrator has to live with the system. This means making daily, high-stakes choices: Do you grant standing access, or do you require step-up authorization for every single agent and tool?
- The Conservative Route: You bury your administrators under a mountain of approval requests, killing the exact velocity the agents were built to deliver.
- The Optimistic Route: You over-authorize access, exposing the enterprise to massive, silent compromises.
Making these decisions is hard enough on its own, but doing it in isolation for a single application is nearly impossible. A tool access might look completely benign in the vacuum of one application, but when viewed in the context of the agent’s overall function across the enterprise, it could be highly abnormal.
Why Traditional IAM Gets Brittle
The natural instinct from classic Identity and Access Management (IAM) is to pre-authorize access through static policies. That model worked beautifully when the caller population was human and the system cardinality was predictable.
Agent sprawl completely breaks those architectural assumptions for three core reasons:
- An Order of Magnitude More Identities: Enterprises are deploying multiple specialized agents for each individual human user, sending the identity population skyrocketing.
- Multi-Application Access: An agent rarely lives in a single silo. Its entire value proposition relies on seamlessly spanning multiple enterprise systems to get a job done.
- Short-Lived Lifecycles: Many agents are ephemeral. They spin up to execute a specific, time-bound task and tear down within minutes.
You cannot manually create a fine-grained, static policy for every single agent that accurately predicts what should be standing access versus what requires a human interrupt. Static policies simply cannot scale to this velocity or volume.
Standing Access is About Behavior, Not Policy
Deciding what is harmless enough to allow without a human prompt is a question about what normal looks like—and static policy alone cannot answer it.
Policy can tell you that an agent is technically permitted to execute queries. It cannot tell you that this specific agent, acting for a specific team, has read the exact same three database tables every weekday afternoon for the last two months and has never once written a single entry.
The way forward is to build a behavioral baseline model for each individual agent to mathematically define its ordinary operational shape, tracking variables like:
- Which tools are invoked across various systems
- Which underlying resources are touched
- Data volume and payload sizes
- Timing patterns and execution schedules
- On whose behalf the agent is acting
The Core Philosophy: The point of a behavioral baseline is to earn the architectural right to stop asking for permission. Once the system maps out this baseline model, the administrator simply reviews and approves the agent's expected behavioral "shape." The system then automates everything inside those boundaries, allowing routine calls to flow seamlessly as standing access.
A Baseline is Only as Sharp as its Dimensions
The accuracy of this baseline relies entirely on the resolution of the data you feed it. As we’ve argued before, governing tools alone is insufficient—you must govern the specific resources those tools operate on. Knowing that an agent called run_query tells you nothing about whether it hit public marketing tables or a restricted finance schema.
That exact visibility gap reappears the moment you try to build a behavior model. If you learn an agent's normal shape only at the tool level, your model simply records that it calls run_query on weekday afternoons. You have successfully described the verb while staying completely blind to the object.
At the tool layer, an agent that safely reads public marketing data looks identical to an agent that is quietly draining your core financial ledger. They look like the exact same Model Context Protocol (MCP) tool call.
The resource is the critical dimension that makes the behavior model honest. With it, "this agent runs queries" becomes "this agent reads these specific tables, for these specific users, at this volume." Without the resource dimension, a behavioral model is fundamentally blind.
Deviation is the Trigger, Not the Verdict
If standing access is what sits comfortably inside the baseline, then a baseline deviation is what pulls a call back into review—even if the underlying tool permission is technically valid. If an agent that has only ever touched marketing data suddenly reaches for a finance table, its tool permission hasn't expired, but its behavioral intent has drifted.
Because 90% of enterprise applications lack the native capability to detect these anomalies, the inline AI Gateway is the ideal place to handle this problem.
Sitting between the agent and your applications, the gateway has the global visibility required to look across silos. It maps out the agent's broad operational blueprint, detects structural deviations in flight, and dynamically triggers human approval before letting a risky call through.
The next step for the AI Gateway is using this rich context to derive intent. By understanding the broader mission of the caller, the gateway can examine a tool invocation and recognize that, for Agent-1, this is a completely valid access to a specific resource, whereas for Agent-2, the same call is highly suspect and must trigger a human-in-the-loop.
Turning Deviations into Decisions Without Drowning Admins
A deviation queue that routes every single anomaly to a human administrator will quickly be ignored. Not every behavioral drift carries the same architectural weight. A minor variance in query volume during a peak business cycle is fundamentally different from an uncharacteristic write operation against a production database.
To keep things manageable, the gateway scores deviations dynamically by evaluating contextual risk signals:
How This Works in Practice
Consider a reporting agent whose baseline consists of read-only access to analytics tables on behalf of the finance team during standard business hours.
Scenario A: Automated Clearance:
- One afternoon, the agent issues a read against a new analytics table it has never touched before. This is a behavioral deviation, so it exits standing access. However, the gateway evaluates the context: it’s a read operation, the table sits within the same authorized analytics schema, and the human analyst in the loop has valid corporate entitlements to that data.
- The Verdict: The risk score is low. The gateway auto-approves the call, updates the baseline, and writes a structured log to the audit ledger. The administrator is never interrupted.
Scenario B: Human Escalation
- The exact same agent, operating at midnight on behalf of a user who left the finance department last quarter, issues a write command against a core production database.
- The Verdict: The deviation triggers, but resource sensitivity, anomalous timing, and stale human entitlements push the risk score to its maximum threshold. The gateway halts execution and escalates the request to the admin queue—already enriched with the exact context explaining why it was flagged.
The goal of automated triage is not to completely eliminate the human element from enterprise security. It is to focus human attention exclusively on the exceptions where that attention actually alters the outcome.
Conclusion
Cryptographic identity gets the agent to the door. Resource governance and the user’s real permissions decide which rooms it may legally enter. Behavior baselines, learned and enforced at the AI Gateway, decide which of those entries are routine enough to be waved through and which genuinely require human intervention.
By mapping the agent's intent across multiple applications, the gateway serves as the thin line between an intelligent security control that holds and an infrastructure team that has tuned out the noise.
At Andromeda, we are building agentic security along exactly these lines. We extend our context of human and non-human identity so that standing access, deviation tracking, and risk-based approvals operate seamlessly, securely, and quietly on your behalf.